
Prediction du Taux Churn
Prévision du taux de Churn – Comparaison de plusieurs Machine Learning
Le taux de churn désigne la proportion des clients que perd une entreprise sur une période donnée. C’est un indicateur marketing clé pour mesurer la fidélité de sa clientèle et un signe d’intérêt que portent les clients aux produits ou service de la marque. Le taux de churn est un indicateur de performance critique pour les entreprises avec un business model basé sur l’abonnement comme le Telecom, Streaming Vidéos music (Netflix, Spotify,..), SaaS,… Il est important pour les entreprises de se concentrer sur la notion de churn car ce taux permet d’analyser la satisfaction de la clientèle et par extension leur rentabilité. Sans oublier le cout d’acquittions d’un nouveau client requiert des budgets importants.
Des études réalisées estiment les dépenses consacrées à l’acquisition client comme étant 5 fois supérieures à celles consacréesà la rétention.
Pourquoi prévoir le Taux de Churn ?
Détecter les clients avec un risque potentiel de churn à l’avance permet de cibler ces personnes afin de l’empêcher de mettre fin à son abonnement. Aussi, avoir la capacité de prédire avec précision le taux de churn est nécessaire car cela permet à l’entreprise de mieux comprendre les revenus futurs attendus. La prévision de taux churn peut également aider à prendre des décisions proactives et améliorer les domaines dans lesquels le service client fait défaut. Prévoir le taux churn par des machine Learning Dans cet article, nous allons créer des modèles de prévision de taux churn basé sur une base de données de Telecom.
Les données ont été fourni par IBM Developer Platform et disponible ici. Certaines informations, telles le nom, les données du client ont été gardés anaonyme par souci de confidentialité mais sans impact sur nos models. L’objectif est déterminer si le client a churné (Yes/No) c’est problem de classement en utilisant plusieurs Machine Learnig pour pouvoir comparer leur performance de prévision. J’utilise la library caret combiné avec le fabuleux library purrr le processus classique d’un Data Science:
- Imporation des données
- Exploration des données
- Split des données
- Preprocessing
- Modélisation
- Evaluation
L’objectif est d’identifier les client perdus (Churn = yes) à partir de leurs caractéristique (gender, SeniorCitizen, Partner, Dependens, tenure,… ). C’est un exercice de classement
Imporation des données
library(readr)
library(dplyr)
library(purrr)
library(tibble)
Customer_Churn <- read_csv("D:/Data/ChurnPrediction/WA_Fn-UseC_-Telco-Customer-Churn.csv")
Customer_Churn%>%glimpse()## Rows: 7,043
## Columns: 21
## $ customerID <chr> "7590-VHVEG", "5575-GNVDE", "3668-QPYBK", "7795-CF...
## $ gender <chr> "Female", "Male", "Male", "Male", "Female", "Femal...
## $ SeniorCitizen <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ Partner <chr> "Yes", "No", "No", "No", "No", "No", "No", "No", "...
## $ Dependents <chr> "No", "No", "No", "No", "No", "No", "Yes", "No", "...
## $ tenure <dbl> 1, 34, 2, 45, 2, 8, 22, 10, 28, 62, 13, 16, 58, 49...
## $ PhoneService <chr> "No", "Yes", "Yes", "No", "Yes", "Yes", "Yes", "No...
## $ MultipleLines <chr> "No phone service", "No", "No", "No phone service"...
## $ InternetService <chr> "DSL", "DSL", "DSL", "DSL", "Fiber optic", "Fiber ...
## $ OnlineSecurity <chr> "No", "Yes", "Yes", "Yes", "No", "No", "No", "Yes"...
## $ OnlineBackup <chr> "Yes", "No", "Yes", "No", "No", "No", "Yes", "No",...
## $ DeviceProtection <chr> "No", "Yes", "No", "Yes", "No", "Yes", "No", "No",...
## $ TechSupport <chr> "No", "No", "No", "Yes", "No", "No", "No", "No", "...
## $ StreamingTV <chr> "No", "No", "No", "No", "No", "Yes", "Yes", "No", ...
## $ StreamingMovies <chr> "No", "No", "No", "No", "No", "Yes", "No", "No", "...
## $ Contract <chr> "Month-to-month", "One year", "Month-to-month", "O...
## $ PaperlessBilling <chr> "Yes", "No", "Yes", "No", "Yes", "Yes", "Yes", "No...
## $ PaymentMethod <chr> "Electronic check", "Mailed check", "Mailed check"...
## $ MonthlyCharges <dbl> 29.85, 56.95, 53.85, 42.30, 70.70, 99.65, 89.10, 2...
## $ TotalCharges <dbl> 29.85, 1889.50, 108.15, 1840.75, 151.65, 820.50, 1...
## $ Churn <chr> "No", "No", "Yes", "No", "Yes", "Yes", "No", "No",...Nous disposons de 7043 observations et 20 variables, dont la cible Churn
Exploration des données
Exploration est la première étape. Le Package summarytools permet de faire une analyse descriptive des variables numériques et catégorielles. La fonction dfSummary est utilisé pour résumer les données, des statistique descriptives, ainsi des graphes pour montrer la distribution
library(summarytools)
print(dfSummary(Customer_Churn%>%select(-customerID), graph.magnif = .7), method= "render")Data Frame Summary
Customer_Churn
Dimensions: 7043 x 20Duplicates: 22
| No | Variable | Stats / Values | Freqs (% of Valid) | Graph | Valid | Missing | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gender [character] | 1. Female 2. Male |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 2 | SeniorCitizen [numeric] | Min : 0 Mean : 0.2 Max : 1 |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 3 | Partner [character] | 1. No 2. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 4 | Dependents [character] | 1. No 2. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 5 | tenure [numeric] | Mean (sd) : 32.4 (24.6) min < med < max: 0 < 29 < 72 IQR (CV) : 46 (0.8) | 73 distinct values |  |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 6 | PhoneService [character] | 1. No 2. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 7 | MultipleLines [character] | 1. No 2. No phone service 3. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 8 | InternetService [character] | 1. DSL 2. Fiber optic 3. No |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 9 | OnlineSecurity [character] | 1. No 2. No internet service 3. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 10 | OnlineBackup [character] | 1. No 2. No internet service 3. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 11 | DeviceProtection [character] | 1. No 2. No internet service 3. Yes |
|
|
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 12 | TechSupport [character] | 1. No 2. No internet service 3. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 13 | StreamingTV [character] | 1. No 2. No internet service 3. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 14 | StreamingMovies [character] | 1. No 2. No internet service 3. Yes |
|
|
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 15 | Contract [character] | 1. Month-to-month 2. One year 3. Two year |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 16 | PaperlessBilling [character] | 1. No 2. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 17 | PaymentMethod [character] | 1. Bank transfer (automatic) 2. Credit card (automatic) 3. Electronic check 4. Mailed check |
|
 |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 18 | MonthlyCharges [numeric] | Mean (sd) : 64.8 (30.1) min < med < max: 18.2 < 70.3 < 118.8 IQR (CV) : 54.3 (0.5) | 1585 distinct values |  |
7043 (100.0%) | 0 (0.0%) | ||||||||||||||||
| 19 | TotalCharges [numeric] | Mean (sd) : 2283.3 (2266.8) min < med < max: 18.8 < 1397.5 < 8684.8 IQR (CV) : 3393.3 (1) | 6530 distinct values |  |
7032 (99.8%) | 11 (0.2%) | ||||||||||||||||
| 20 | Churn [character] | 1. No 2. Yes |
|
 |
7043 (100.0%) | 0 (0.0%) |
Generated by summarytools 0.9.8 (R version 4.0.3)
2021-02-28
Comme on peut le voir ci-dessous, le type de variable est affiché avec le nom. Viennent ensuite des statistiques descriptives pour les variables numériques et les valeurs des variables catégorielle. Un simple histogramme ou graphe avec des barres est affiché. Aussi, s’il y a des valeurs manquantes ou erreurs. Le Report fournit un résumé concis de l’ensemble des variables dans les données
On peut supprimer certains lignes (TotalCharges) avec des erreurs (11 lignes), sans impact sur les données.
Customer_Churn<- Customer_Churn%>%tidyr::drop_na()A l’aide de ggplot, on peut aussi visualiser les variables numériques et catégorielles séparément avec le variable Churn
library(tidyverse)
library(ggthemes)
theme_set(theme_minimal())Graphe pour les variables catégorielle
Customer_Churn%>%
mutate(SeniorCitizen = as.character(SeniorCitizen))%>%
select(- customerID)%>%
select_if(is.character)%>%
select(Churn, everything())%>%
gather(x, y, gender:PaymentMethod)%>%
count(Churn, x, y)%>%
ggplot(aes(x=y, y=n, fill = Churn, color=Churn))+
facet_wrap(~ x, ncol= 3, scales= "free")+
geom_bar(stat = "identity", alpha = 0.5)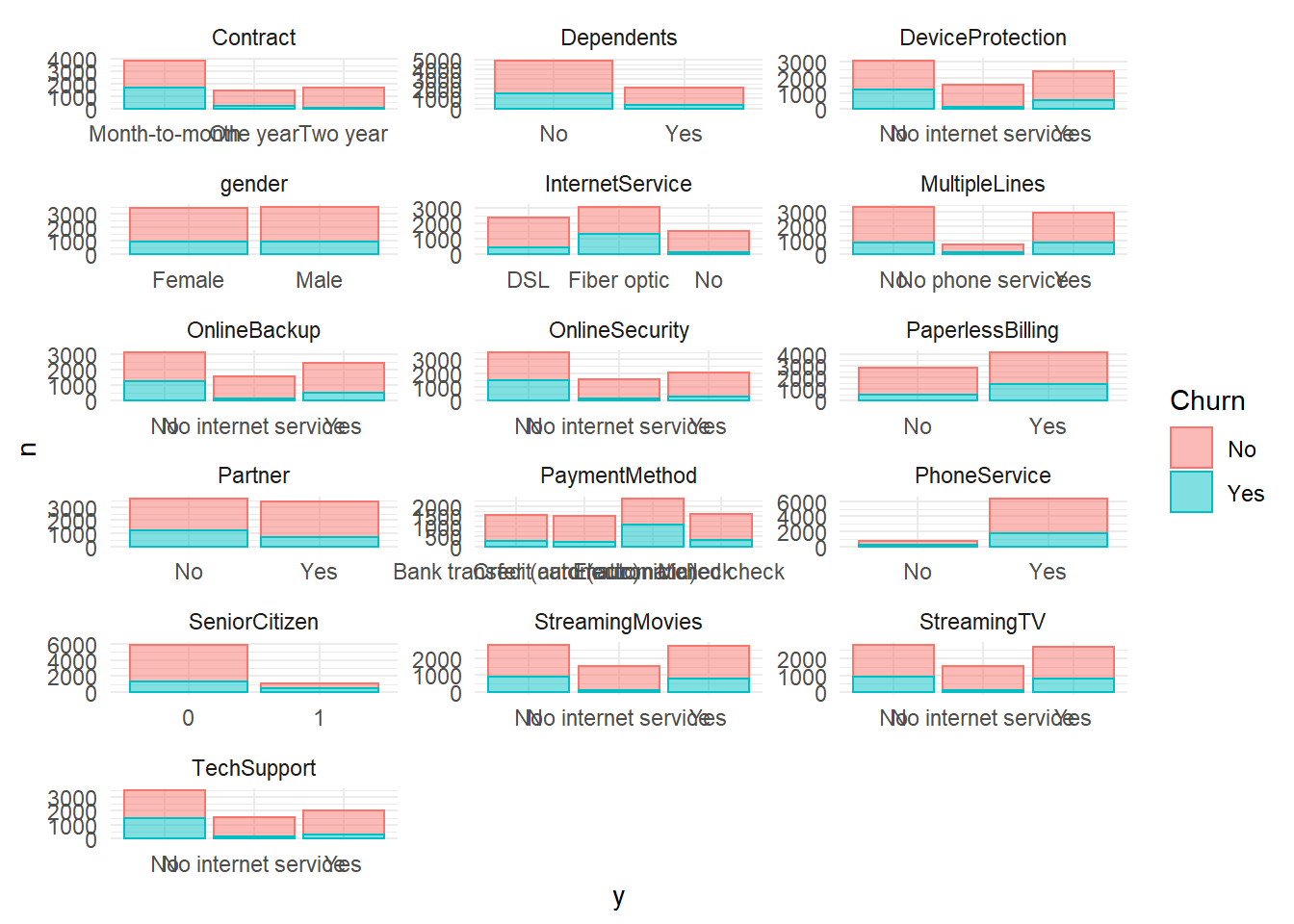
Graphe pour les variables numériques
Customer_Churn%>%
select(- customerID)%>%
select(Churn, MonthlyCharges, tenure, TotalCharges) %>%
gather(x, y, MonthlyCharges:TotalCharges)%>%
count(Churn, x, y)%>%
ggplot(aes(x=y, fill = Churn, color=Churn))+
facet_wrap(~ x, ncol= 3, scales= "free")+
geom_density( alpha = 0.5)+
scale_color_tableau()+
scale_fill_tableau()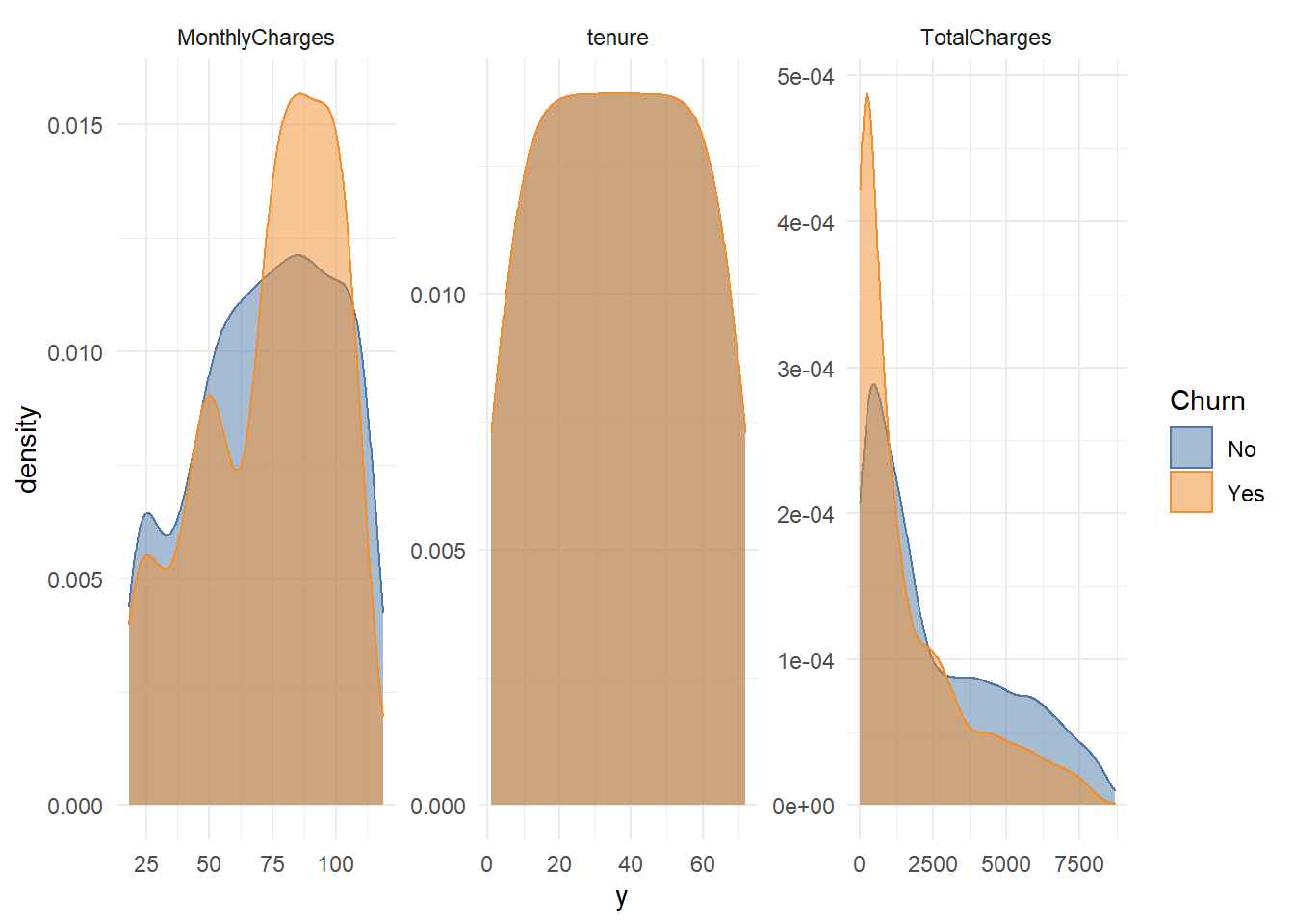
Split des données
On scinde les données en deux, train pour la modélisation 80% et test 20% pour l’évaluation de nos modèles afin d’éviter le sur-apprentissage
library(rsample)
set.seed(123)
index_split<- initial_split(Customer_Churn, prop = 0.8)
train_data<- training(index_split)
test_data<- testing(index_split)
index_split## <Analysis/Assess/Total>
## <5626/1406/7032>print(train_data%>%nrow())## [1] 5626print(test_data%>%nrow)## [1] 1406Preprocessing
Les différences échelles ou de distribution entre les variables peuvent diverger des hypothéses sous-jacent dans les modèles. Il est donc nécessaire d’appliquer des tâches step de modification de la distribution ou rendre les valeurs texte en numérique (dummy Variables). Le package recipes permet la manipulation facile de la phase de prétraitement. L’objet crée rec_obj permet de stocker tous les étapes de preprocessing
library(recipes)
rec_obj<- recipe(Churn ~ ., Customer_Churn) %>%
step_rm(customerID) %>% # supprimer le variable customerID
step_naomit(all_outcomes(), all_predictors()) %>% # supprimer les lignes avec erreur
step_discretize(tenure, options = list(cuts = 6)) %>% # convertir valeur numérique en catégorie par tranche
step_log(TotalCharges) %>% # appliquer log pour Totalcharges - bcq outliers
step_dummy(all_nominal(), -all_outcomes()) %>% # convertir les valeur text en numérique--Encodage des valeurs catégorielle
step_center(all_predictors(), -all_outcomes()) %>% # Standarisation (centré)
step_scale(all_predictors(), -all_outcomes()) %>% # standarisation
prep()
rec_obj## Data Recipe
##
## Inputs:
##
## role #variables
## outcome 1
## predictor 20
##
## Training data contained 7032 data points and no missing data.
##
## Operations:
##
## Variables removed customerID [trained]
## Removing rows with NA values in all_outcomes(), all_predictors()
## Dummy variables from tenure [trained]
## Log transformation on TotalCharges [trained]
## Dummy variables from gender, Partner, Dependents, tenure, ... [trained]
## Centering for SeniorCitizen, MonthlyCharges, ... [trained]
## Scaling for SeniorCitizen, MonthlyCharges, ... [trained]On applique l’objet sur nos données train et test
train_data_prep <- bake(rec_obj, new_data = train_data)%>%
select(Churn, everything())
test_data_prep<- bake(rec_obj, new_data= test_data)%>%
select(Churn, everything())Aprés la transformation
train_data_prep%>%
glimpse()## Rows: 5,626
## Columns: 36
## $ Churn <fct> No, Yes, No, Yes, Yes, No, No...
## $ SeniorCitizen <dbl> -0.4402958, -0.4402958, -0.44...
## $ MonthlyCharges <dbl> -0.2608594, -0.3638974, -0.74...
## $ TotalCharges <dbl> 0.389269024, -1.452520489, 0....
## $ gender_Male <dbl> 0.9905875, 0.9905875, 0.99058...
## $ Partner_Yes <dbl> -0.9655394, -0.9655394, -0.96...
## $ Dependents_Yes <dbl> -0.6522585, -0.6522585, -0.65...
## $ tenure_bin1 <dbl> -0.4597167, 2.1749433, -0.459...
## $ tenure_bin2 <dbl> -0.4382227, -0.4382227, -0.43...
## $ tenure_bin3 <dbl> -0.4531211, -0.4531211, -0.45...
## $ tenure_bin4 <dbl> 2.2370543, -0.4469528, 2.2370...
## $ tenure_bin5 <dbl> -0.452209, -0.452209, -0.4522...
## $ tenure_bin6 <dbl> -0.4326772, -0.4326772, -0.43...
## $ PhoneService_Yes <dbl> 0.3271661, 0.3271661, -3.0561...
## $ MultipleLines_No.phone.service <dbl> -0.3271661, -0.3271661, 3.056...
## $ MultipleLines_Yes <dbl> -0.8542748, -0.8542748, -0.85...
## $ InternetService_Fiber.optic <dbl> -0.8868334, -0.8868334, -0.88...
## $ InternetService_No <dbl> -0.5250931, -0.5250931, -0.52...
## $ OnlineSecurity_No.internet.service <dbl> -0.5250931, -0.5250931, -0.52...
## $ OnlineSecurity_Yes <dbl> 1.5778061, 1.5778061, 1.57780...
## $ OnlineBackup_No.internet.service <dbl> -0.5250931, -0.5250931, -0.52...
## $ OnlineBackup_Yes <dbl> -0.725464, 1.378232, -0.72546...
## $ DeviceProtection_No.internet.service <dbl> -0.5250931, -0.5250931, -0.52...
## $ DeviceProtection_Yes <dbl> 1.3812738, -0.7238665, 1.3812...
## $ TechSupport_No.internet.service <dbl> -0.5250931, -0.5250931, -0.52...
## $ TechSupport_Yes <dbl> -0.6392149, -0.6392149, 1.564...
## $ StreamingTV_No.internet.service <dbl> -0.5250931, -0.5250931, -0.52...
## $ StreamingTV_Yes <dbl> -0.7901296, -0.7901296, -0.79...
## $ StreamingMovies_No.internet.service <dbl> -0.5250931, -0.5250931, -0.52...
## $ StreamingMovies_Yes <dbl> -0.7967925, -0.7967925, -0.79...
## $ Contract_One.year <dbl> 1.9433571, -0.5145003, 1.9433...
## $ Contract_Two.year <dbl> -0.5613245, -0.5613245, -0.56...
## $ PaperlessBilling_Yes <dbl> -1.2062754, 0.8288802, -1.206...
## $ PaymentMethod_Credit.card..automatic. <dbl> -0.5253134, -0.5253134, -0.52...
## $ PaymentMethod_Electronic.check <dbl> -0.7118128, -0.7118128, -0.71...
## $ PaymentMethod_Mailed.check <dbl> 1.8394452, 1.8394452, -0.5435...Modélisation
On va créer une fonction pour nous faciliter l’utilisation du package caret. C’est un package qui permet d’appeler de nombreuses méthodes de machine learning en offrant une interface unifiée et qui comporte des fonctions utilitaires diverses. Appeler la fonction getModelInfo() pour avoir les informations grâce auxquelles caret sait utiliser les différentes librairies. Mais avant, trainControl, on utilise une validation croisée en 5 bloc et répétés 3 fois La validation croisée consiste à partager aléatoirement l’échantillon en V segment (blocs) puis itérativement à faire jouer chacune de ses segments de rôle d’échantillon de validation tandis que les V-1 autres consistent l’échantillon d’apprentissage servant à estimer le modèle. Il existe d’autres techniques
library(caret)
fitCtl <- trainControl(method = "repeatedcv",
number = 5,
repeats = 3)
mlFuncFact <- function(ml_method) {
function(data, label) {
caret::train(
x = data%>%select(-Churn),
y = label,
method = ml_method,
trControl = fitCtl,
)
}
}Après, on crée une liste des modèles de Machines Learning à comparer : arbre de décision, Random Forest, knn, Xgboost et gbm. Vous la liste compélete des modèles disponible ici
- Arbre de décision : C’est une des méthodes d’apprentissage supervisé les plus populaires pour les problèmes de classification de données. plus
- Random Forest :L’algorithme des « forêts aléatoires » (ou Random Forest parfois aussi traduit par forêt d’arbres décisionnels) est un algorithme de classification qui réduit la variance des prévisions d’un arbre de décision seul, améliorant ainsi leurs performances. Pour cela, il combine de nombreux arbres de décisions dans une approche de type bagging. plus
- Knn, k-Nearest Neighbours : c’est un algorithme standard de classification qui repose exclusivement sur le choix de la métrique de classification. Il est “non paramétrique” (seul k doit être fixé) et se base uniquement sur les données d’entraînement.plus
- Xgboost (comme eXtreme Gradient Boosting) est une implémentation open source optimisée de l’algorithme d’arbres de boosting de gradient GBM.Gradient Boosting Machine, est un algorithme d’apprentissage supervisé dont le principe et de combiner les résultats d’un ensemble de modèles plus simple et plus faibles afin de fournir une meilleur prédiction.plus
model_df <- list(
decision_tree = mlFuncFact('rpart2'),
random_forest = mlFuncFact('ranger'),
boosted_log_reg = mlFuncFact('LogitBoost'),
knn = mlFuncFact('knn'),
#gbm = mlFuncFact('gbm'),
xgb_tree = mlFuncFact('xgbTree')
) %>%
enframe(name = 'model', value = 'model_func')
model_df## # A tibble: 5 x 2
## model model_func
## <chr> <list>
## 1 decision_tree <fn>
## 2 random_forest <fn>
## 3 boosted_log_reg <fn>
## 4 knn <fn>
## 5 xgb_tree <fn>La fonction train ne se contente pas simplement d’appeler la fonction d’apprentissage de la librairie correspondant à la méthode, elle optimise aussi les paramètres. On ajoute nos données de train (échantillon d’apprentissage) et de test.
data<-tibble(Training = list(train_data_prep))%>%
mutate(label_train = purrr::map(Training, "Churn"),
Testing = list(test_data_prep))
model<- data%>%
tidyr::crossing(model_df)
model## # A tibble: 5 x 5
## Training label_train Testing model model_func
## <list> <list> <list> <chr> <list>
## 1 <tibble [5,626 x 3~ <fct [5,626]> <tibble [1,406 x 3~ boosted_log_~ <fn>
## 2 <tibble [5,626 x 3~ <fct [5,626]> <tibble [1,406 x 3~ decision_tree <fn>
## 3 <tibble [5,626 x 3~ <fct [5,626]> <tibble [1,406 x 3~ knn <fn>
## 4 <tibble [5,626 x 3~ <fct [5,626]> <tibble [1,406 x 3~ random_forest <fn>
## 5 <tibble [5,626 x 3~ <fct [5,626]> <tibble [1,406 x 3~ xgb_tree <fn>On construits nos modèles à l’aide de la fonction invoke_map qui va appliquer les méthodes sectionnées à notre dataset. Ca va prendre un peu de temps…
library(tictoc)
tic()
trained_model<-model%>%
mutate(model_params = map2(Training, label_train, ~ list(data = .x, label= .y)),
model_train = invoke_map(model_func,model_params ))
trained_model## # A tibble: 5 x 7
## Training label_train Testing model model_func model_params model_train
## <list> <list> <list> <chr> <list> <list> <list>
## 1 <tibble [5~ <fct [5,626~ <tibble [~ boost~ <fn> <named list~ <train>
## 2 <tibble [5~ <fct [5,626~ <tibble [~ decis~ <fn> <named list~ <train>
## 3 <tibble [5~ <fct [5,626~ <tibble [~ knn <fn> <named list~ <train>
## 4 <tibble [5~ <fct [5,626~ <tibble [~ rando~ <fn> <named list~ <train>
## 5 <tibble [5~ <fct [5,626~ <tibble [~ xgb_t~ <fn> <named list~ <train>toc()## 253.55 sec elapsedOn test la qualité de nos modèles sur l’échantillon Test avec la fonction predict et on mesure la performance à l’aide de Matrix de confusion confusionMatrix
tic()
pred<-trained_model%>%mutate(pred = map2(model_train,Testing, function(.model_train, .Testing) predict(.model_train, .Testing)))
pred<-pred%>%mutate(ConfusionM = map2(pred, Testing, function(.pred, .Testing) confusionMatrix(.pred, .Testing$Churn)))
pred## # A tibble: 5 x 9
## Training label_train Testing model model_func model_params model_train pred
## <list> <list> <list> <chr> <list> <list> <list> <lis>
## 1 <tibble~ <fct [5,62~ <tibbl~ boos~ <fn> <named list~ <train> <fct~
## 2 <tibble~ <fct [5,62~ <tibbl~ deci~ <fn> <named list~ <train> <fct~
## 3 <tibble~ <fct [5,62~ <tibbl~ knn <fn> <named list~ <train> <fct~
## 4 <tibble~ <fct [5,62~ <tibbl~ rand~ <fn> <named list~ <train> <fct~
## 5 <tibble~ <fct [5,62~ <tibbl~ xgb_~ <fn> <named list~ <train> <fct~
## # ... with 1 more variable: ConfusionM <list>toc()## 0.47 sec elapsedOn peut aussi mesurer le taux de succés Accuracy
accuracy <-pred%>%
mutate(
accuracy_InSample = map_dbl(model_train, ~max(.x$results$Accuracy)),
accuracy_OutSample = map_dbl(ConfusionM, ~max(.x$overall[['Accuracy']])),
accuracySD_InfSample = map_dbl(model_train, ~max(.x$results$AccuracySD)))%>%
select(model, accuracy_InSample, accuracy_OutSample, accuracySD_InfSample)%>%
arrange(desc(accuracy_OutSample))
accuracy## # A tibble: 5 x 4
## model accuracy_InSample accuracy_OutSample accuracySD_InfSample
## <chr> <dbl> <dbl> <dbl>
## 1 xgb_tree 0.809 0.793 0.0154
## 2 random_forest 0.794 0.785 0.0117
## 3 boosted_log_reg 0.788 0.784 0.0161
## 4 knn 0.785 0.779 0.0102
## 5 decision_tree 0.786 0.772 0.0149Sur les paramètres de base de chaque modèle, on a pu avoir un taux de réussite de 78%-80%. Le meilleur algorithme est Xgboost
Mesure Biais et dispersion
accuracy%>%
ggplot(aes(x=model, colour = model))+
geom_point(aes(y = accuracy_InSample), size =2)+
geom_errorbar(aes(ymin = accuracy_InSample - accuracySD_InfSample,
ymax = accuracy_InSample + accuracySD_InfSample ))+
scale_x_discrete()+
theme_classic()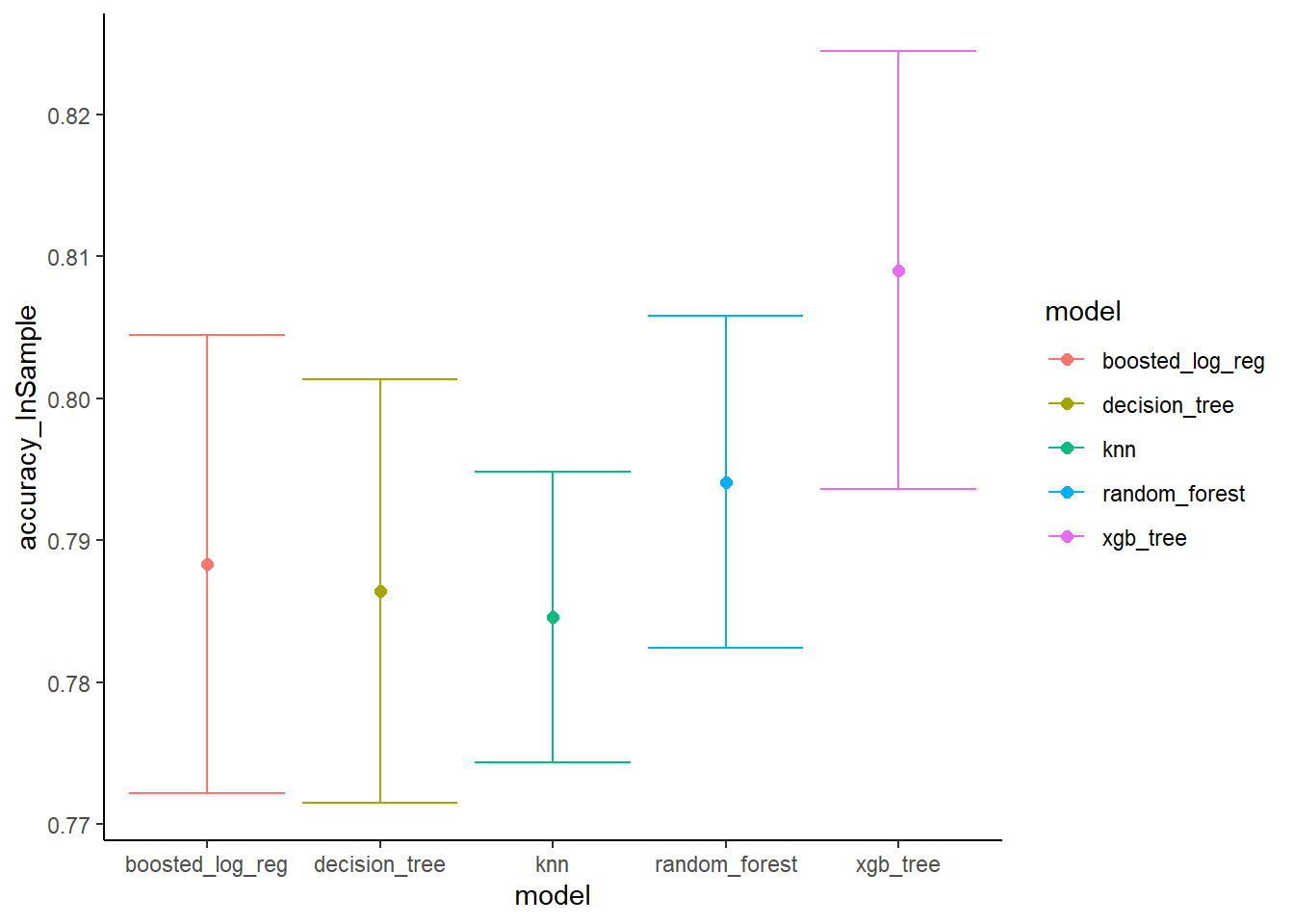
Comparaison de mesure de accuracy par Modéle sur les données train et test pour vérifier un overfitting
library(ggrepel)
accuracy%>%
ggplot(aes(x=accuracy_InSample, y =accuracy_OutSample ))+
geom_point(aes(colour =model ), size =2)+
geom_vline(aes(xintercept = min(accuracy_InSample)), linetype = 5, colour = "gray50")+
geom_hline(aes(yintercept = min(accuracy_OutSample)), linetype = 5, colour = "gray50")+
ggrepel::geom_label_repel(aes(label = model), size = 3.5, segment.colour = "gray30", data = accuracy)+
theme(legend.position = "none")+
labs( x = " Taux de réussite In-Sample ", y = " Taux de réussite Out-Sample ", colour = "Family")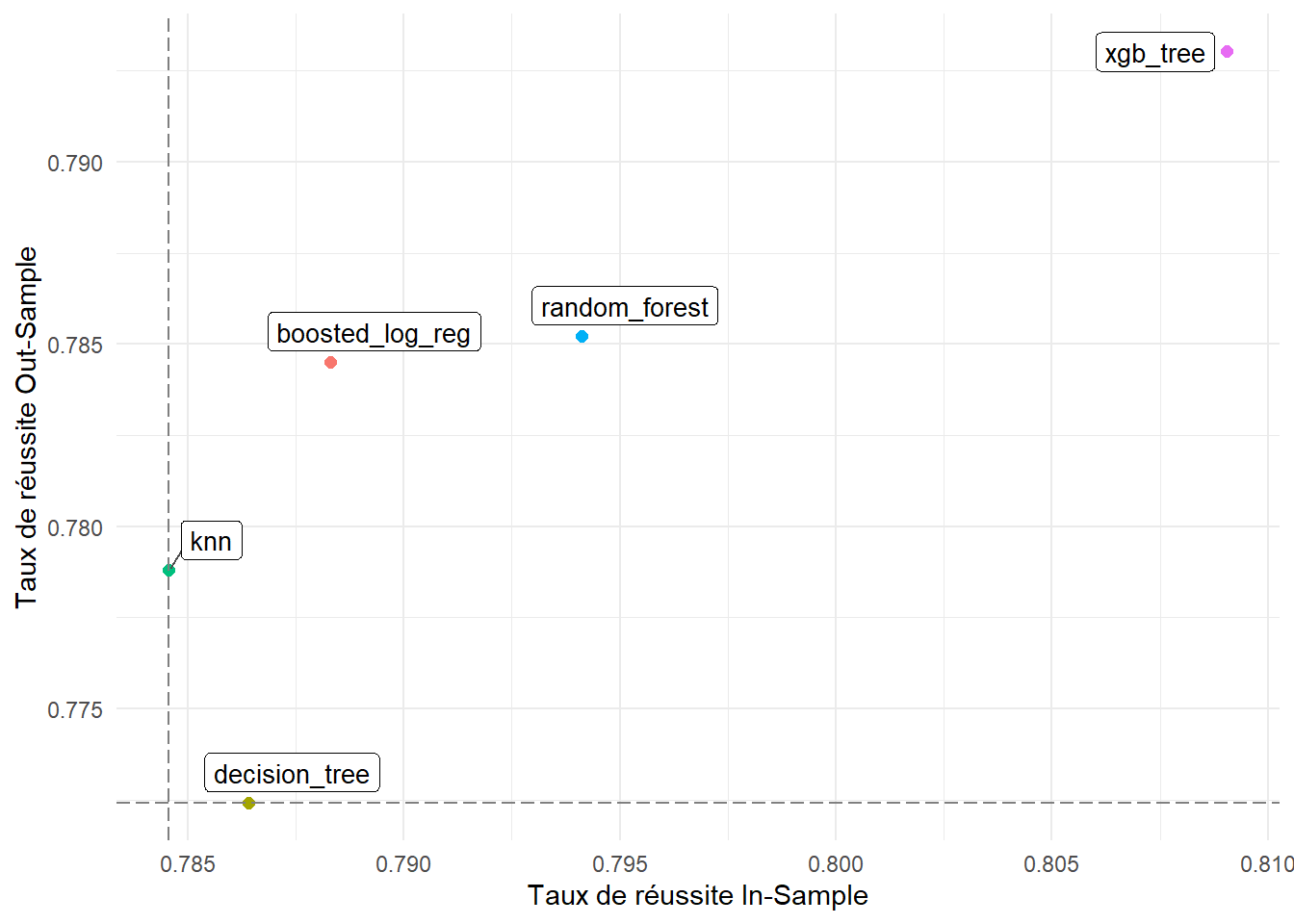
On peut améliorer la performance de notre algorithme en procédant au Tuning des paramètres comme le nombre d’arbre, Learning Rate, max_depth,… Les paramétres disponible dans le modèle xgbTree
getModelInfo("xgbTree")$xgbTree$parameters## parameter class label
## 1 nrounds numeric # Boosting Iterations
## 2 max_depth numeric Max Tree Depth
## 3 eta numeric Shrinkage
## 4 gamma numeric Minimum Loss Reduction
## 5 colsample_bytree numeric Subsample Ratio of Columns
## 6 min_child_weight numeric Minimum Sum of Instance Weight
## 7 subsample numeric Subsample Percentage